Dubbo 之类的RPC调用需要采用负载均衡算法,负载均衡目的是是将网络请求,或者其他形式的负载“均摊”到不同的机器上。在 Dubbo 中有四种实现方法,在业务中比较常用的就是一致性哈希算法,它能够保证同一个 key 的请求能放到同一台机器上,主要针对一些具有缓存的业务。
在 Dubbo 服务 Provider 上下线时,因为需要重新计算一致性哈希的原因,会导致消费端线程堵塞。
问题发生
问题分析
在服务端正常重启 Dubbo 服务时,接收到了 Consumer 端的机器报警,Cunsumer 端虚拟机的 Load 在重启阶段快速升高,在重启完后又很快下降。因为是稳定复现的线上问题,于是需要进行排查。
利用在线服务诊断平台 [bistoury] (https://github.com/qunarcorp/bistoury)的记录, JStack 打印了当时机器升高时的异常栈,发现有大量线程在进行 Dubbo 调用,点开其线程栈后发现几乎所有的线程都在 com.alibaba.dubbo.rpc.cluster.loadbalance.ConsistentHashLoadBalance$ConsistentHashSelector.(ConsistentHashSelector.java:117) 这里卡住了,这里是是重新计算一致性哈希节点时的代码。
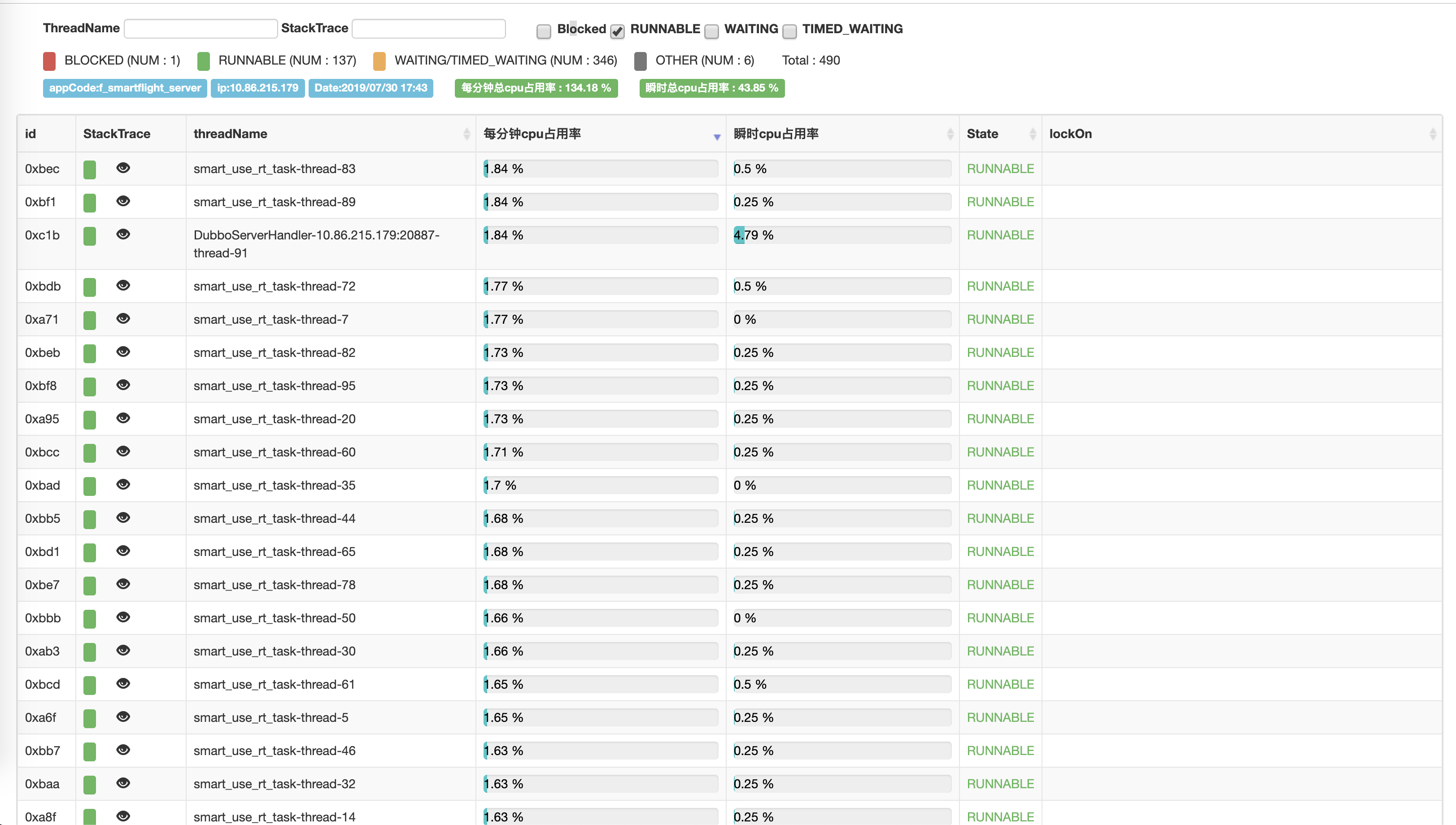
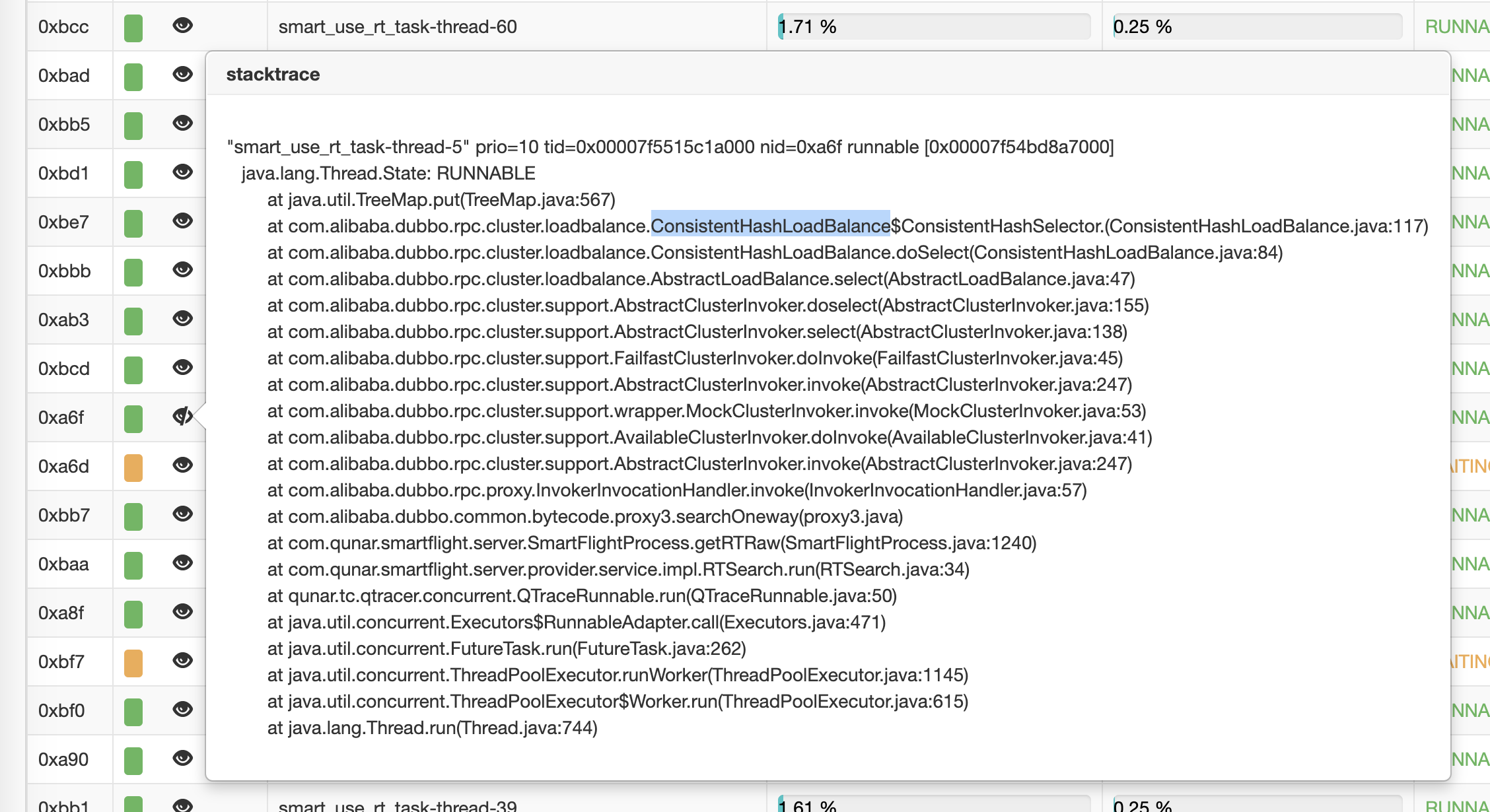
经过对一致性哈希源码的分析,发现是在线上高并发场景下,所有的调用都在重新计算哈希节点,计算耗费 CPU 时间,导致所有的任务都卡住了。
1 | //经过简化的业务代码 |
这是进行 Dubbo调用的地方,可以看出在一瞬间消费端会并发发出大量的请求(通过分析日志是 30ms 内有 32 个请求),而通过单测在线上配置虚拟节点为 640 的情况下,一致性哈希的计算时间为 28ms,所以同时计算占用了大量 CPU 时间,导致系统 Load 升高。
解决方案
通过对这边代码的分析,得出解决方案为:
- 降低虚拟节点数量,这个可以有效降低一致性哈希的计算时间,降低 CPU 占用。但是会导致一定程度上哈希虚拟节点分布不够均匀,产生热点 key 和 热点机器。
- 对 Dubbo 提供的一致性哈希算法进行重写,对重新计算哈希节点的代码进行加锁,只要有一个正在计算让其他线程都进入 wait 状态。这样可以保证不用每个线程都重新计算哈希节点。但是需要考虑锁释放后其他线程的惊群效应,让系统状态恶化。
源码分析
一致性哈希算法
通过参考 Dubbo 官方文档中有关 负载均衡 的内容,分析其一致性哈希算法的实现。
一致性 hash 算法由麻省理工学院的 Karger 及其合作者于1997年提出的,算法提出之初是用于大规模缓存系统的负载均衡。它的工作过程是这样的,首先根据 ip 或者其他的信息为缓存节点生成一个 hash,并将这个 hash 投射到 [0, 232 - 1] 的圆环上。当有查询或写入请求时,则为缓存项的 key 生成一个 hash 值。然后查找第一个大于或等于该 hash 值的缓存节点,并到这个节点中查询或写入缓存项。如果当前节点挂了,则在下一次查询或写入缓存时,为缓存项查找另一个大于其 hash 值的缓存节点即可。大致效果如下图所示,每个缓存节点在圆环上占据一个位置。如果缓存项的 key 的 hash 值小于缓存节点 hash 值,则到该缓存节点中存储或读取缓存项。比如下面绿色点对应的缓存项将会被存储到 cache-2 节点中。由于 cache-3 挂了,原本应该存到该节点中的缓存项最终会存储到 cache-4 节点中。

下面来看看一致性 hash 在 Dubbo 中的应用。我们把上图的缓存节点替换成 Dubbo 的服务提供者,于是得到了下图:

这里相同颜色的节点均属于同一个服务提供者,比如 Invoker1-1,Invoker1-2,……, Invoker1-160。这样做的目的是通过引入虚拟节点,让 Invoker 在圆环上分散开来,避免数据倾斜问题。所谓数据倾斜是指,由于节点不够分散,导致大量请求落到了同一个节点上,而其他节点只会接收到了少量请求的情况。比如:

如上,由于 Invoker-1 和 Invoker-2 在圆环上分布不均,导致系统中75%的请求都会落到 Invoker-1 上,只有 25% 的请求会落到 Invoker-2 上。解决这个问题办法是引入虚拟节点,通过虚拟节点均衡各个节点的请求量。
一致性哈希算法的入口在com.alibaba.dubbo.rpc.cluster.loadbalance.ConsistentHashLoadBalance#doSelect中。主要对 invokers 进行了判断,如果 invokers 是一个新的 List 对象,意味着 Provider 数量发生了变化。
1 | if (selector == null || selector.identityHashCode != identityHashCode) { |
以上是判断了哈希环是否需要初始化,以下就是初始化的过程
1 | private static final class ConsistentHashSelector<T> { |
在初始化完成或不需要初始化的情况下,调用 select 方法选择 Invoker
1 | public Invoker<T> select(Invocation invocation) { |
以上就是一致性哈希计算的主要过程,就是将参数进行 md5 和 hash 计算,得到一个 hash 值。然后再拿这个值到 TreeMap 中查找目标 Invoker 即可。